| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- wazuh agent 설치
- iis url rewrite
- 특정 도메인 url rewrite
- Prometheus
- grafana esxi 모니터링
- FortiGate
- http 리디렉션
- IBM X3550 M4
- ubuntu 22.04+Prometheus+Grafana+Node Exporter
- Node Exporter 설치 및 연동
- wazuh 설치
- observium 설정
- grafana
- grafana telegraf influxdb esxi 모니터링
- wazuh 서버 설치
- MSCS
- https 자동전환
- telegraf esxi 모니터링
- piolink
- grafana esxi monitoring
- wazuh 취약점 점검
- prometheus grafana 연동
- URL 재작성
- IIS https 무한루프
- telegraf influxdb
- grafana vsphere
- grafana esxio
- centos
- grafana vcenter
- grafana esxi
- Today
- Total
IDC 엔지니어의 기술 이야기
Grafana+Telegraf+influxDB 연동을 통한 Vmware Esxi 모니터 본문
환경 : Ubuntu 22.04 LTS
Grafana : 10.1.5
InfluxDB : 2.7.4
Telegraf : 1.28.5-1
참고URL : https://ko.linux-console.net/?p=21626
참고URL : https://grafana.com/grafana/dashboards/8168-vmware-vsphere-vms/
Grafana 및 Telegraf를 사용하여 VMware ESXi 모니터링 |
안녕하세요 여러분!. 여기서는 Grafana, Telegraf 및 InfluxDB를 사용하여 VMware ESXi 인프라를 모니터링하는 가장 효율적이고 놀라운 방법을 제시합니다. 설정은 매우 간단하며 30분 이내에 Grafana에서 VMwa
ko.linux-console.net
전체 로직 : Telegraf 데이터 수집 > InfluxDB 데이터 저장 > Grafana에서 InfluxDB 데이터 연동
초록색 : 명령어 입력
파랑색 : 설정 입력(Vi,Nano등)
빨강색 : 주석
ㅁ Grafana 설치
1. Grafana 패키지 저장소 추가하기
root@grafana:~# sudo apt-get install -y apt-transport-https gnupg2 curl
root@grafana:~# curl https://packages.grafana.com/gpg.key | sudo apt-key add -
root@grafana:~# echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
root@grafana:~# sudo apt-get update
2. Grafana 설치
root@grafana:~# sudo apt-get install -y grafana
3. Grafana 실행
root@grafana:~# sudo systemctl enable grafana-server
root@grafana:~# sudo systemctl start grafana-server
root@grafana:~# sudo systemctl status grafana-server

Grafana 실행 확인
4. Grafana 접속
http://Prometheus 서버IP:3000/
초기 ID/PW : admin / admin
ㅁ Influx DB 설치
1. Influx DB 패키지 설치
> 저장소 추가
root@grafana:~# echo "deb https://repos.influxdata.com/ubuntu focal stable" | tee /etc/apt/sources.list.d/influxdb.list
> GPG키 추가
root@grafana:~# curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
>저장소 업데이트
root@grafana:~# apt update
>패키지 설치
root@grafana:~# apt install -y influxdb2
> 서비스 시작 및 활성화
root@grafana:~# systemctl enable --now influxdb
> 서비스 확인
root@grafana:~# ps -ef | grep influxdb
influxdb 8311 1 0 09:47 ? 00:00:00 /usr/bin/influxd
root 8345 6722 0 09:48 pts/1 00:00:00 grep --color=auto influxdb
root@grafana:~# netstat -nlpt | grep 8086
tcp6 0 0 :::8086 :::* LISTEN 8311/influxd
2. InfluxDB 설정
> Web 접근
http://192.168.43.35:8086/

> 설정 정보 입력(나중에 Telegraf 및 Grafana 설정시에 필요한 정보 들이니 메모해 둘것)
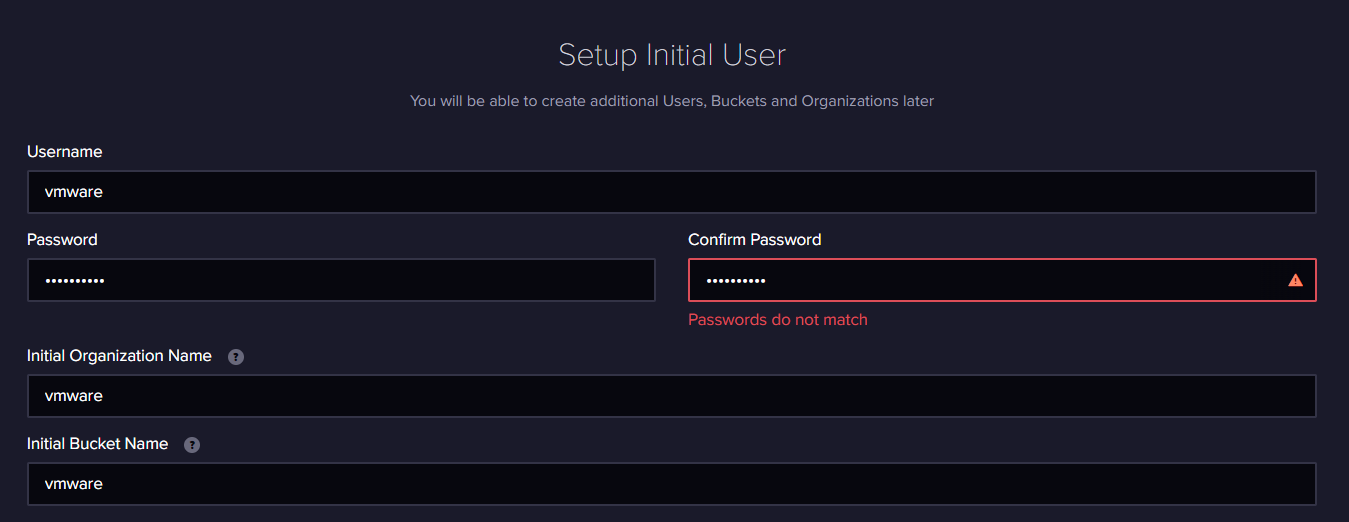
> API Token 생성


"API Tokens 클릭후 > GENERATE API TOKEN > All Access API Token" 적절한 이름으로 생성후 Token Key 메모장에 복사해 놓기
ㅁ Telegraf 설치
1. Telegraf 패키지 설치
root@grafana:~# sudo apt-get -y install telegraf
2. Telegraf 설정
root@grafana:~# vi /etc/telegraf/telegraf.conf
> InfluxDB 데이터 삽입 정보 설정
[[outputs.influxdb_v2]]
urls = ["http://127.0.0.1:8086"] // Influx DB 접근 경로
token = "LP3x-5f_lLUFZZpkwC3kiHdsfdsfdsfdsfdsfXjq62e6gDTRHjSzWyzDA==" // infulxDB 설정시 생성한 User Token
organization = "vmware" // influxDB 설정시 생성한 org
bucket = "vmware" // influxDB 설정시 생성한 bucket
timeout = "5s" // 데이터 입력시 Timeout 설정
> 모니터링한 Esxi Vcenter 설정
[[inputs.vsphere]]
vcenters = [ "https://10.10.10.10/sdk" ] // Vcenter 접속 정보
username = "administrator" // Vcenter 접근 ID
password = "esxi2012" // Vcenter 패스워드
> 모니터링 항목 및 인증서 관련 설정(필요한 항목만 주석해제, 아래 내용은 공식사이트 권고사항)
# ## VMs
# ## Typical VM metrics (if omitted or empty, all metrics are collected)
# # vm_include = [ "/*/vm/**"] # Inventory path to VMs to collect (by default all are collected)
# # vm_exclude = [] # Inventory paths to exclude
vm_metric_include = [
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.run.summation",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.wait.summation",
"mem.active.average",
"mem.granted.average",
"mem.latency.average",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.usage.average",
"power.power.average",
"virtualDisk.numberReadAveraged.average",
"virtualDisk.numberWriteAveraged.average",
"virtualDisk.read.average",
"virtualDisk.readOIO.latest",
"virtualDisk.throughput.usage.average",
"virtualDisk.totalReadLatency.average",
"virtualDisk.totalWriteLatency.average",
"virtualDisk.write.average",
"virtualDisk.writeOIO.latest",
"sys.uptime.latest",
]
# # vm_metric_exclude = [] ## Nothing is excluded by default
# # vm_instances = true ## true by default
#
## Hosts
# ## Typical host metrics (if omitted or empty, all metrics are collected)
# # host_include = [ "/*/host/**"] # Inventory path to hosts to collect (by default all are collected)
# # host_exclude [] # Inventory paths to exclude
host_metric_include = [
"cpu.coreUtilization.average",
"cpu.costop.summation",
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.swapwait.summation",
"cpu.usage.average",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.utilization.average",
"cpu.wait.summation",
"disk.deviceReadLatency.average",
"disk.deviceWriteLatency.average",
"disk.kernelReadLatency.average",
"disk.kernelWriteLatency.average",
"disk.numberReadAveraged.average",
"disk.numberWriteAveraged.average",
"disk.read.average",
"disk.totalReadLatency.average",
"disk.totalWriteLatency.average",
"disk.write.average",
"mem.active.average",
"mem.latency.average",
"mehttp://m.state.latest",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.totalCapacity.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.errorsRx.summation",
"net.errorsTx.summation",
"net.usage.average",
"power.power.average",
"storageAdapter.numberReadAveraged.average",
"storageAdapter.numberWriteAveraged.average",
"storageAdapter.read.average",
"storageAdapter.write.average",
"sys.uptime.latest",
]
# ## Collect IP addresses? Valid values are "ipv4" and "ipv6"
# # ip_addresses = ["ipv6", "ipv4" ]
#
# # host_metric_exclude = [] ## Nothing excluded by default
# # host_instances = true ## true by default
#
#
# ## Clusters
# # cluster_include = [ "/*/host/**"] # Inventory path to clusters to collect (by default all are collected)
# # cluster_exclude = [] # Inventory paths to exclude
cluster_metric_include = [] ## if omitted or empty, all metrics are collected
# # cluster_metric_exclude = [] ## Nothing excluded by default
# # cluster_instances = false ## false by default
#
# ## Resource Pools
# # resource_pool_include = [ "/*/host/**"] # Inventory path to resource pools to collect (by default all are collected)
# # resource_pool_exclude = [] # Inventory paths to exclude
# # resource_pool_metric_include = [] ## if omitted or empty, all metrics are collected
# # resource_pool_metric_exclude = [] ## Nothing excluded by default
# # resource_pool_instances = false ## false by default
#
# ## Datastores
# # datastore_include = [ "/*/datastore/**"] # Inventory path to datastores to collect (by default all are collected)
# # datastore_exclude = [] # Inventory paths to exclude
datastore_metric_include = [] ## if omitted or empty, all metrics are collected
# # datastore_metric_exclude = [] ## Nothing excluded by default
# # datastore_instances = false ## false by default
#
# ## Datacenters
# # datacenter_include = [ "/*/host/**"] # Inventory path to clusters to collect (by default all are collected)
# # datacenter_exclude = [] # Inventory paths to exclude
datacenter_metric_include = [] ## if omitted or empty, all metrics are collected
# datacenter_metric_exclude = [ "*" ] ## Datacenters are not collected by default.
# # datacenter_instances = false ## false by default
#
# ## VSAN
# # vsan_metric_include = [] ## if omitted or empty, all metrics are collected
# # vsan_metric_exclude = [ "*" ] ## vSAN are not collected by default.
# ## Whether to skip verifying vSAN metrics against the ones from GetSupportedEntityTypes API.
# # vsan_metric_skip_verify = false ## false by default.
#
# ## Interval for sampling vSAN performance metrics, can be reduced down to
# ## 30 seconds for vSAN 8 U1.
# # vsan_interval = "5m"
#
# ## Plugin Settings
# ## separator character to use for measurement and field names (default: "_")
# # separator = "_"
#
# ## number of objects to retrieve per query for realtime resources (vms and hosts)
# ## set to 64 for vCenter 5.5 and 6.0 (default: 256)
# # max_query_objects = 256
#
# ## number of metrics to retrieve per query for non-realtime resources (clusters and datastores)
# ## set to 64 for vCenter 5.5 and 6.0 (default: 256)
# # max_query_metrics = 256
#
# ## number of go routines to use for collection and discovery of objects and metrics
# # collect_concurrency = 1
# # discover_concurrency = 1
#
# ## the interval before (re)discovering objects subject to metrics collection (default: 300s)
# # object_discovery_interval = "300s"
#
# ## timeout applies to any of the api request made to vcenter
# # timeout = "60s"
#
# ## When set to true, all samples are sent as integers. This makes the output
# ## data types backwards compatible with Telegraf 1.9 or lower. Normally all
# ## samples from vCenter, with the exception of percentages, are integer
# ## values, but under some conditions, some averaging takes place internally in
# ## the plugin. Setting this flag to "false" will send values as floats to
# ## preserve the full precision when averaging takes place.
# # use_int_samples = true
#
# ## Custom attributes from vCenter can be very useful for queries in order to slice the
# ## metrics along different dimension and for forming ad-hoc relationships. They are disabled
# ## by default, since they can add a considerable amount of tags to the resulting metrics. To
# ## enable, simply set custom_attribute_exclude to [] (empty set) and use custom_attribute_include
# ## to select the attributes you want to include.
# ## By default, since they can add a considerable amount of tags to the resulting metrics. To
# ## enable, simply set custom_attribute_exclude to [] (empty set) and use custom_attribute_include
# ## to select the attributes you want to include.
# # custom_attribute_include = []
# # custom_attribute_exclude = ["*"]
#
# ## The number of vSphere 5 minute metric collection cycles to look back for non-realtime metrics. In
# ## some versions (6.7, 7.0 and possible more), certain metrics, such as cluster metrics, may be reported
# ## with a significant delay (>30min). If this happens, try increasing this number. Please note that increasing
# ## it too much may cause performance issues.
# # metric_lookback = 3
#
# ## Optional SSL Config
# # ssl_ca = "/path/to/cafile"
# # ssl_cert = "/path/to/certfile"
# # ssl_key = "/path/to/keyfile"
# ## Use SSL but skip chain & host verification
insecure_skip_verify = true
2. Telegraf 시작
root@grafana:~# systemctl enable --now telegraf
root@grafana:~# ps -ef | grep tele
telegraf 9159 1 0 10:34 ? 00:00:00 /usr/bin/telegraf -config /etc/telegraf/telegraf.conf -config-directory /etc/telegraf/telegraf.d
3. InfluxDB 데이터 수집 확인
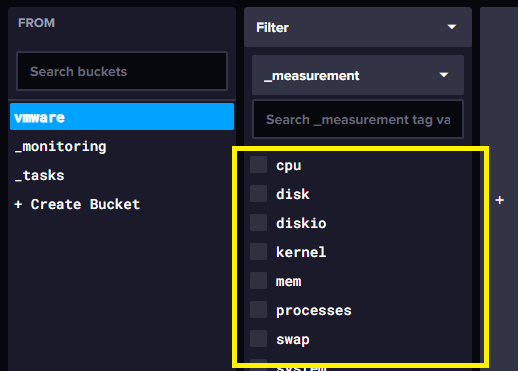
위 그림과 같이 모니터링 수집항목이 보이고 조회가 된다면 정상적으로 데이터를 수집하는 것이다.
ㅁ Grafana <> InfluxDB 연동 및 대쉬보드 설정
1. Grafana에서 InfluxDB Data Source 추가
>> Grafana Data Source 추가 메뉴 클릭
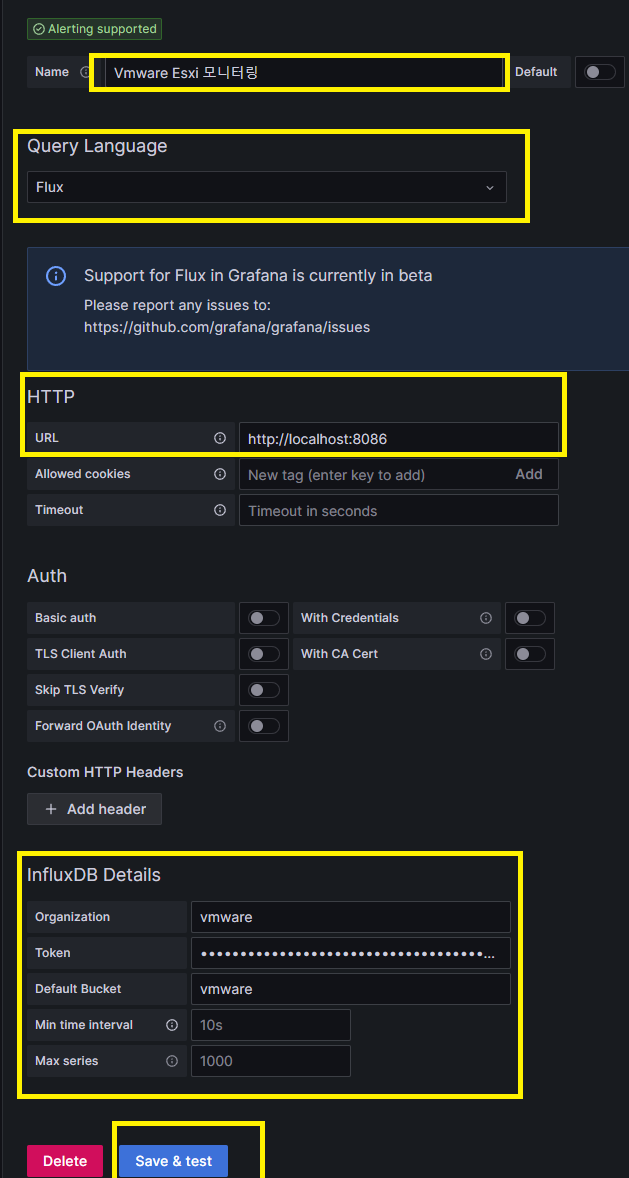
Name : 적당한 이름으로
Query Language : Flux (2.X 버젼이후는 해당 랭귀지로)
HTTP URL : Grafana랑 다른데 설치 되어있다면 적절하게 수정
InfluxDB Details : InfluxDB 설정한 정보 입력

정상적으로 입력시 위와 같은 메시지 확인 가능
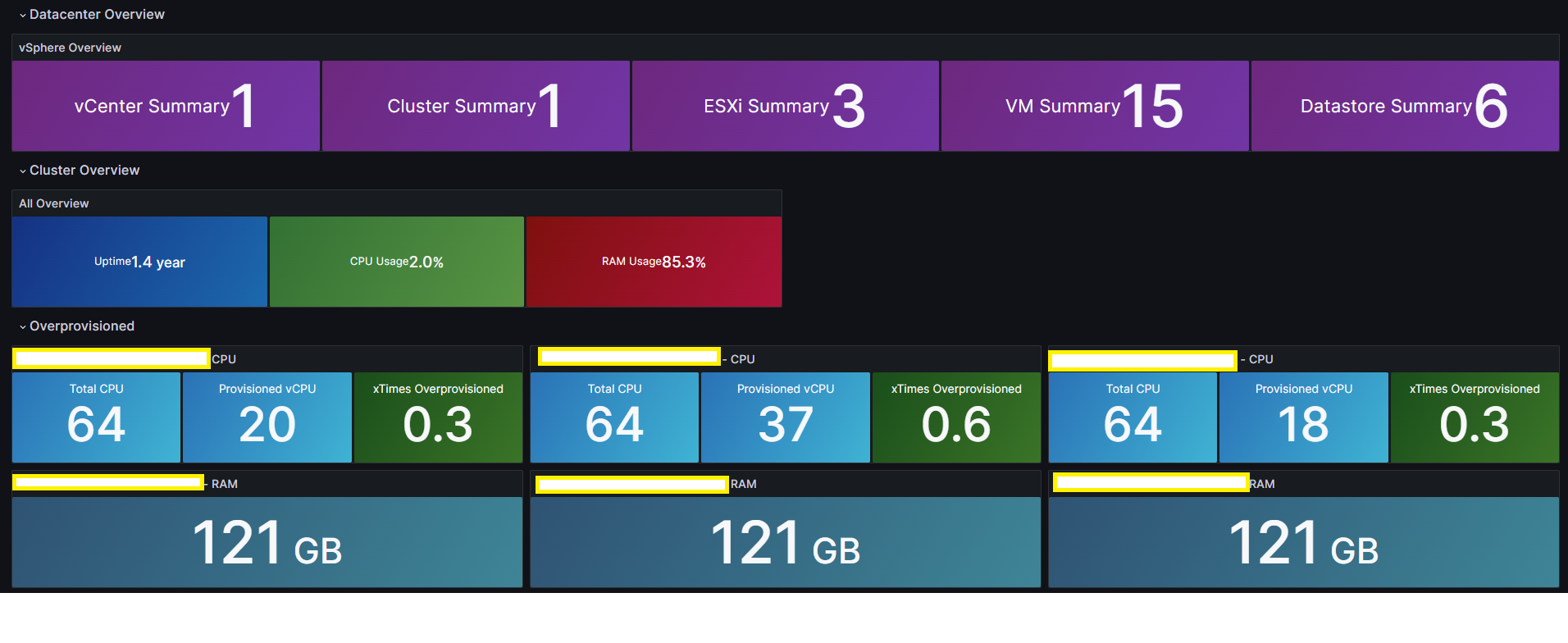
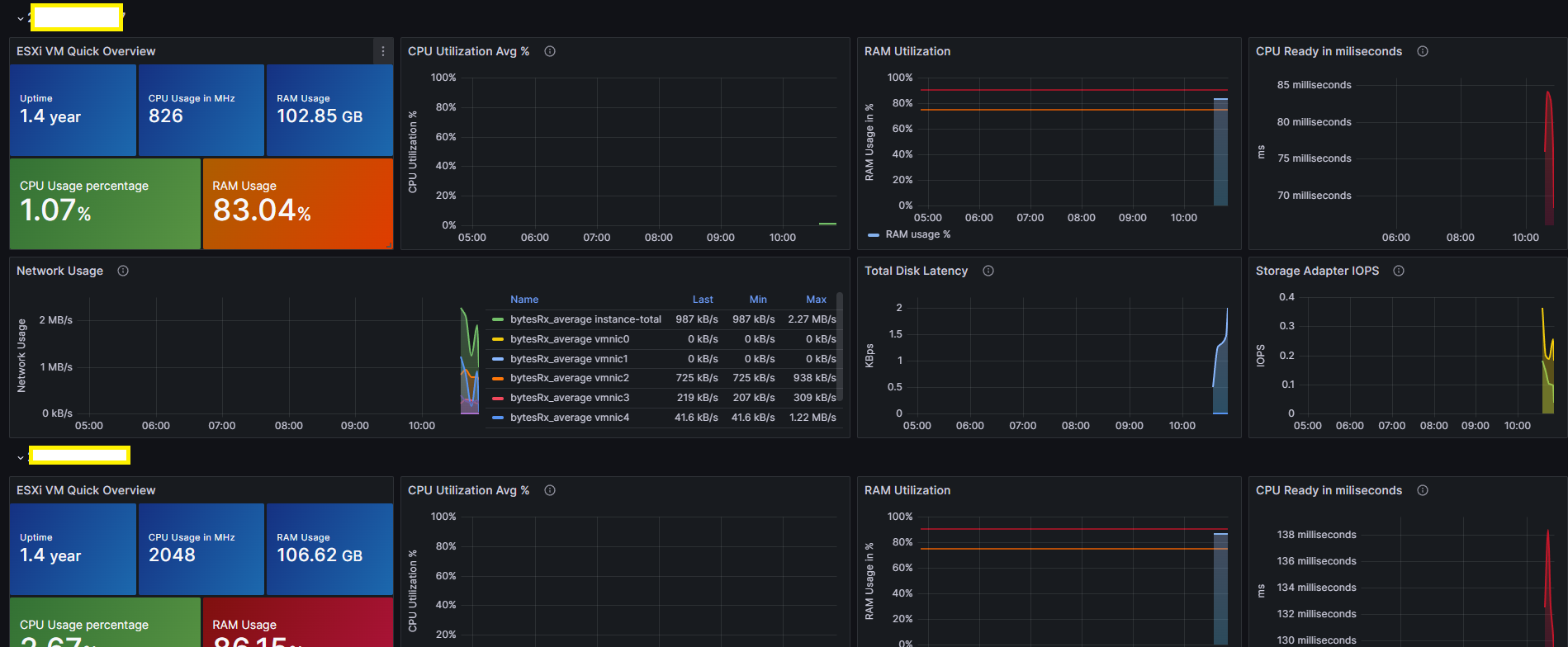
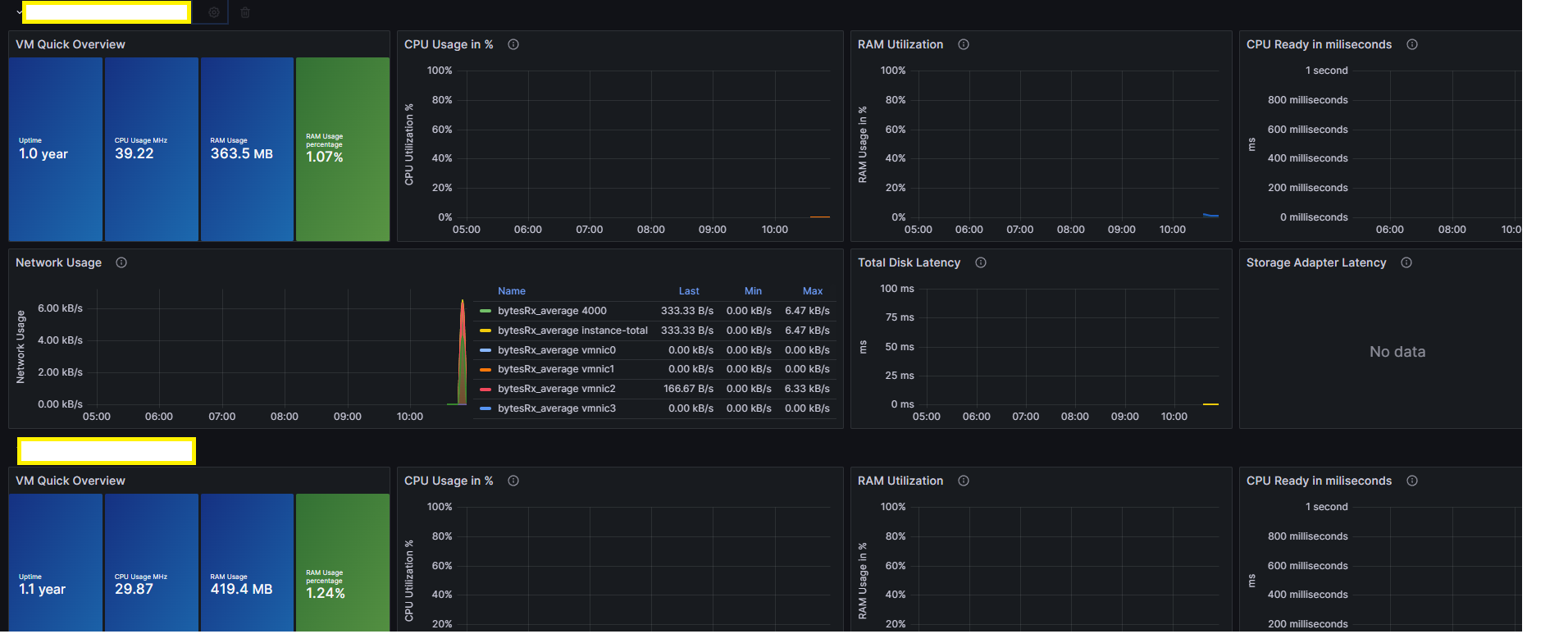
2. Grafana Dashboard 생성
기존에 잘 만들어진 아래 대시보드를 사용하자
- Grafana vSphere 개요 대시보드 – 8159
- Grafana vSphere 데이터스토어 대시보드 – 8162
- Grafana vSphere 호스트 대시보드 – 8165
- Grafana vSphere VM 대시보드 – 8168
'OS_APP > Monitoring' 카테고리의 다른 글
| HIDS Wazuh 서버 구축 (1) | 2023.12.26 |
|---|---|
| Prometheus+Grafana+Exporter 연동 구축 (1) | 2023.10.16 |
| Docker+Prometheus+Grafana+Node Exporter 설치 및 연동 (0) | 2023.09.21 |
| Observium 설정 (0) | 2023.07.04 |
| Observium 설치 (0) | 2023.07.04 |



